
Pytorch入门学习
环境搭建
pytoch|cuda|Python 版本兼容
【Pytorch、torchvision、CUDA 各个版本对应关系以及安装指令】_torch和cuda对应关系-CSDN博客
一文搞懂 PyTorch、CUDA 与 Python 的版本兼容性问题 - 知乎
【环境搭建】Python、PyTorch与cuda的版本对应表_pytorch cuda版本对应关系-CSDN博客
环境版本选定
python 3.10|cuda 11.8| torch 2.2.2
安装命令
1 | conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia |
- 验证torch是否可调用显卡
1 | import torch |
报错原因解决:

numpy2.0修改了底层二进制接口,导致旧版Numpy1.x编译的C/C++扩展模块无法在新版中运行,所以通过回退Numpy版本为1.x
1 | pip install "numpy<2" |
miniconda安装jupyter
- miniconda轻量环境下是不自带jupyter工具的,需要我们手动安装
1 | conda install jupyter # 安装 Jupyter Notebook |
TensorBoard
TensorFlow 官方提供的可视化工具,用于展示机器学习模型的训练过程和结构。它能帮助你更好地理解模型的训练过程、调试问题,以及对比不同模型的效果。
Transforms
在深度学习和计算机视觉里,**Transforms(变换)**指的就是对原始数据进行预处理或增强的一系列操作,目的是让模型更容易学习、提升泛化能力、减轻过拟合。
eg:
ToTensor、Compose、Resize、Normalize、…
Dataloader
Dataloader 是 PyTorch 中用于高效加载和处理数据的核心工具,主要用于将数据集划分为小批次(batches),以便在训练神经网络时进行迭代处理。
神经网络
torch网络层级文档地址:torch.nn — PyTorch 2.7 documentation
基本骨架
1 | from torch import nn |
卷积
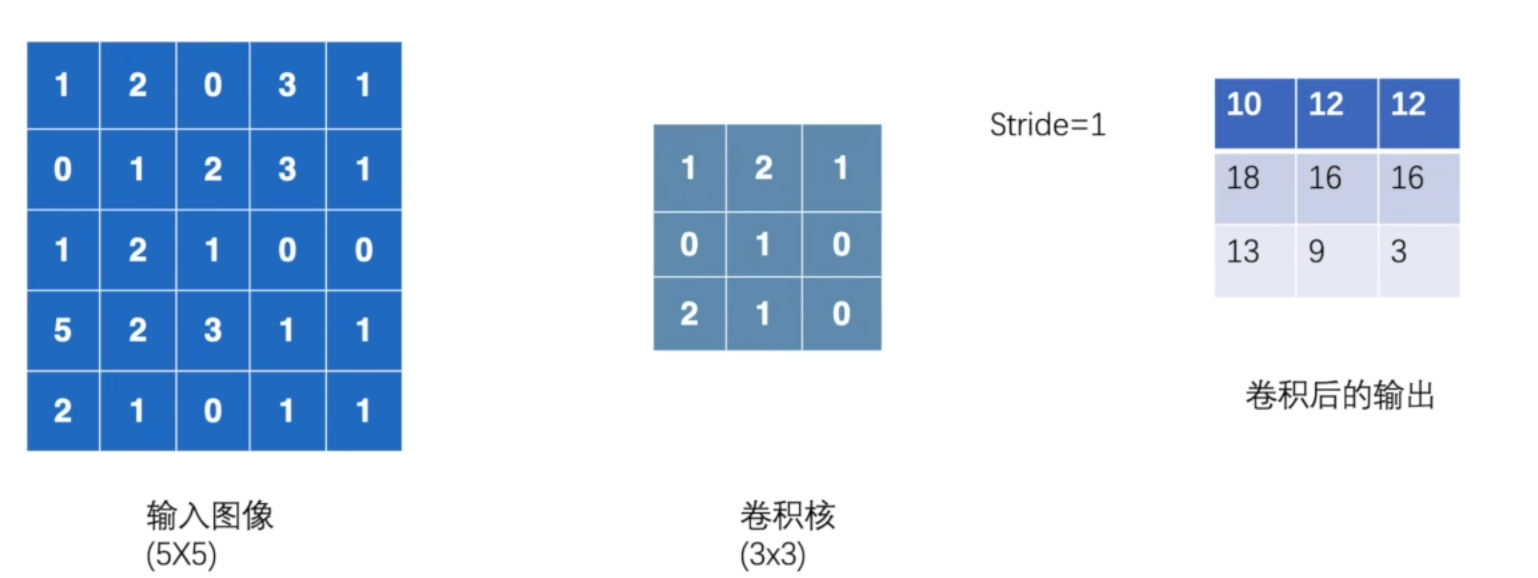
In_channel: 输入通道数
kernel_size: 卷积核大小
stride: 卷积核步进大小
padding: 在输入图像外围填充数值
bias:对卷积后的结果加减一个常数
Out_channel: 输出通道数(即是卷积核数)
1 | import torch |
卷积层
1 | import torchvision |
池化层
- kernel_size: 池化窗口大小
- cell_mode:影响输出特征图的尺寸和边界数据
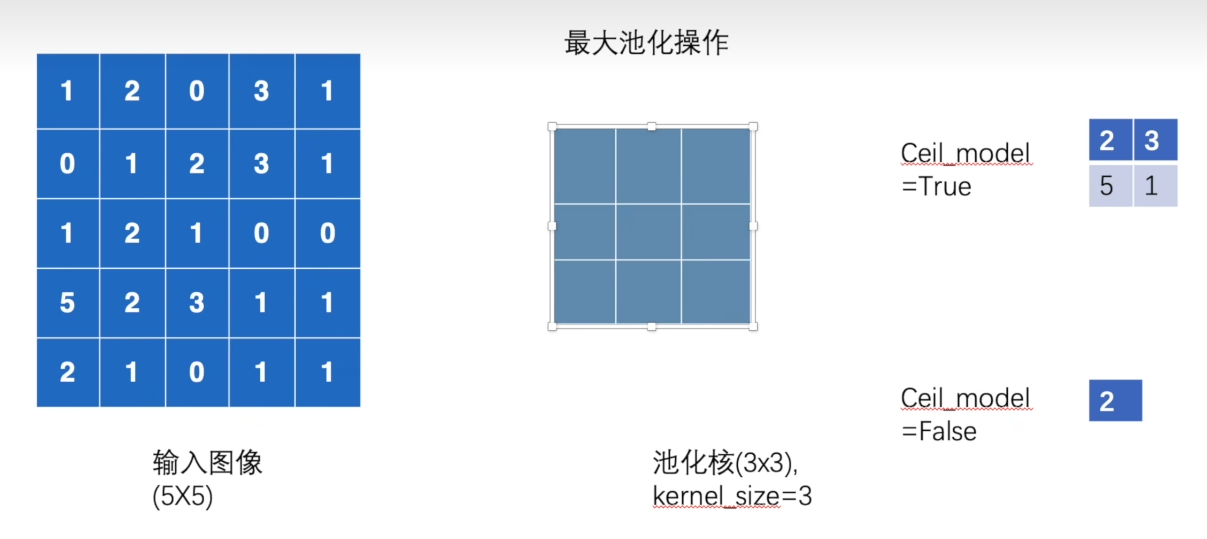
- 最大池化作用,保留输入特征的同时减少数据量
1 | import torch |
非线性激活
**常见激活函数:**relu 、sigmoid
1 | import torch |
正则化层
线性层
“神经网络线性层”通常指的是全连接层(Fully Connected Layer),在 PyTorch 深度学习框架中通常称为 Linear 层。它的本质是一个仿射变换。
$$
\text{output} = W \cdot x + b
$$
- x:输入向量(或张量)
- W:权重矩阵(可训练参数)
- b:偏置向量(可训练参数)
1 | import torch |
sequential
cifar-10 分类模型结构
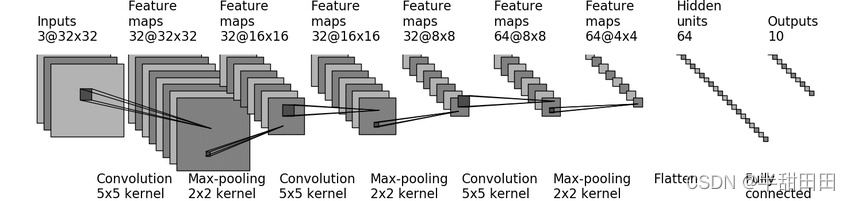
Conv2d 各变量参数计算

stride : 1
padding: 2
1 | from torch import nn |
损失函数(Loss_Function)
- 计算实际输出核目标之间的差距
- 为我们更新输出提供一定的依据(反向传播)
1 | import torch |
优化器
1 | from torch import nn |
模型保存、加载
1 | import torchvision |
1 | import torch |
- 方式1保存加载的时候需要将网络结构复制到加载处(可以不需要定义)
完整模型训练
利用GPU加速训练
方法一
针对
- 网络模型
- 数据(输入、标注)
- 损失函数
在后面调用,cuda()进行加速处理
1 | from doctest import OutputChecker |
方法二
1 | device = torch.device("cuda") |
模型推理测试
1 | import torch |